
More often than not, business leaders looking to automate document processing think they need optical character recognition (OCR), when what they actually need is something far more capable.
For years, OCR was the only accessible way to extract data from documents. It became shorthand for the entire problem. But modern operations now deal with messy, high-volume, highly variable documents – and OCR alone was never designed for that reality.
This guide clarifies what OCR, RPA and Intelligent Document Processing (IDP) really do, where they fall short and how they fit together today. More importantly, it explains why next-generation agentic intelligent document processing exists and how it’s enabling organisations to automate entire document workflows.
If your goal is to reduce manual data entry and avoid brittle automations, it’s important to know the difference between OCR, RPA and IDP.

What OCR actually does (and doesn’t do)
Optical character recognition (OCR) converts images of text into machine-readable characters. OCR can tell you what characters appear on a page, but it doesn’t understand what those characters mean, how they relate to each other or why they matter in a business process.
You might have heard the term ‘intelligent OCR’. In practice, this usually means OCR with some heuristics layered on top (as in, ‘if-this-then-that-’ rules with simple logic). It still doesn’t truly understand context or intent.
OCR is useful when documents are:
- Cleanly scanned
- Highly structured
- Consistent in layout
- Used for simple text extraction
In these cases, OCR is a helpful building block. But it was never meant to be the whole solution. For example, OCR cannot:
- Understand document structure or meaning
- Handle layout changes or vendor variability
- Validate data or apply business logic
- Reason across pages or documents
- Integrate outputs safely into downstream systems
In practice, most organisations aren’t relying on OCR alone.
The term is often used as shorthand for broader document processing tools, which has blurred the distinction between reading text and understanding it. OCR’s role is simply to convert images into text. It does not interpret structure, validate data or apply business logic.
When the goal is true document automation, OCR is just one component in a much more complex system that must understand context, handle variability and safely integrate outputs into downstream workflows.
What RPA does (and why it needs help)
Robotic process automation (RPA) automates actions by mimicking human clicks, keystrokes and system interactions. RPA doesn’t extract data, though. In fact, it assumes the data already exists.
Historically, OCR extracted text and RPA moved that text into downstream business systems, such as ERPs, accounting systems and claims management platforms.
RPA works well for:
- Repetitive, deterministic tasks
- Stable system integrations
- Rule-based workflows
However, it has its limitations. For example, RPA breaks when:
- Inputs are incomplete or inconsistent
- Document formats change
- Exceptions appear
Together, OCR and RPA looked like end-to-end automation. But, maintaining RPA workflows for variable documents quickly became expensive and fragile. Many teams that implement OCR plus RPA discover high exception rates, outputs that they have low confidence in and rising maintenance overheads from additional time spent correcting and optimizing the automations.
The issue with a combined OCR and RPA solution isn’t automation effort – it’s document understanding. That’s where intelligent document processing comes in.
What IDP really is
Intelligent document processing (IDP)combines OCR and RPA with document understanding, and introduces new capabilities like structuring data, validation, business rules and workflow integration.
Leading IDP platforms focus on turning documents into decision-ready data, offering orchestration and governance layers to give teams consistent, traceable outputs.
Earlier IDP platforms relied on machine learning models, often using token classification. They improved flexibility compared to OCR, but introduced new challenges:
- Models required training and retraining
- Labeled datasets were expensive
- Model fleets became complex to manage
This era of IDP improved accuracy, but at the cost of speed and adaptability.
ML-based IDP still struggled with:
- Fast adaptation to new document types
- Cross-document reasoning
- High operational overheads
This created the opening for a new approach and new IDP solutions.

The rise of agentic IDP
Agentic intelligent document processing uses large language models orchestrated by AI agents to understand, extract and validate documents.
Crucially, though, agentic IDP is not ‘just an LLM’. Agentic IDP systems coordinate multiple tools – including OCR, retrieval-augmented generation (RAG), validation and Model Memory – to produce grounded, auditable results.
In simple terms, agentic IDP works like this:
- OCR captures the raw text when needed
- LLMs read and interpret the document
- Retrieval-augmented generation (RAG) grounds outputs in source content
- Validators check totals, dates and IDs
- Memory stores corrections and examples
- Agents orchestrate the workflow end-to-end
Affinda’s Platform combines all of these elements, so understanding, validation and integration happen as one system, not a collection of brittle components. The platform also offers built-in orchestration and governance so teams get consistent, traceable outputs without maintaining a fragile model pipeline.
Agentic intelligent document processing outperforms older approaches because it:
- Works across unfamiliar layouts instantly
- Requires no retraining cycles
- Handles messy, multi-document workflows
- Learns immediately from every document or correction
- Produces evidence-backed outputs
- Reduces technical debt and overheads
The result is faster time-to-value, straight-through processing and decision-ready data.
For operations leaders, this can mean faster turnaround times, less burnout and turnover, and the ability to grow without linear increases in headcount.
For technical teams, it means faster proofs of concept, easier integration into existing systems and no technical debt.
OCR vs RPA vs IDP vs Agentic IDP
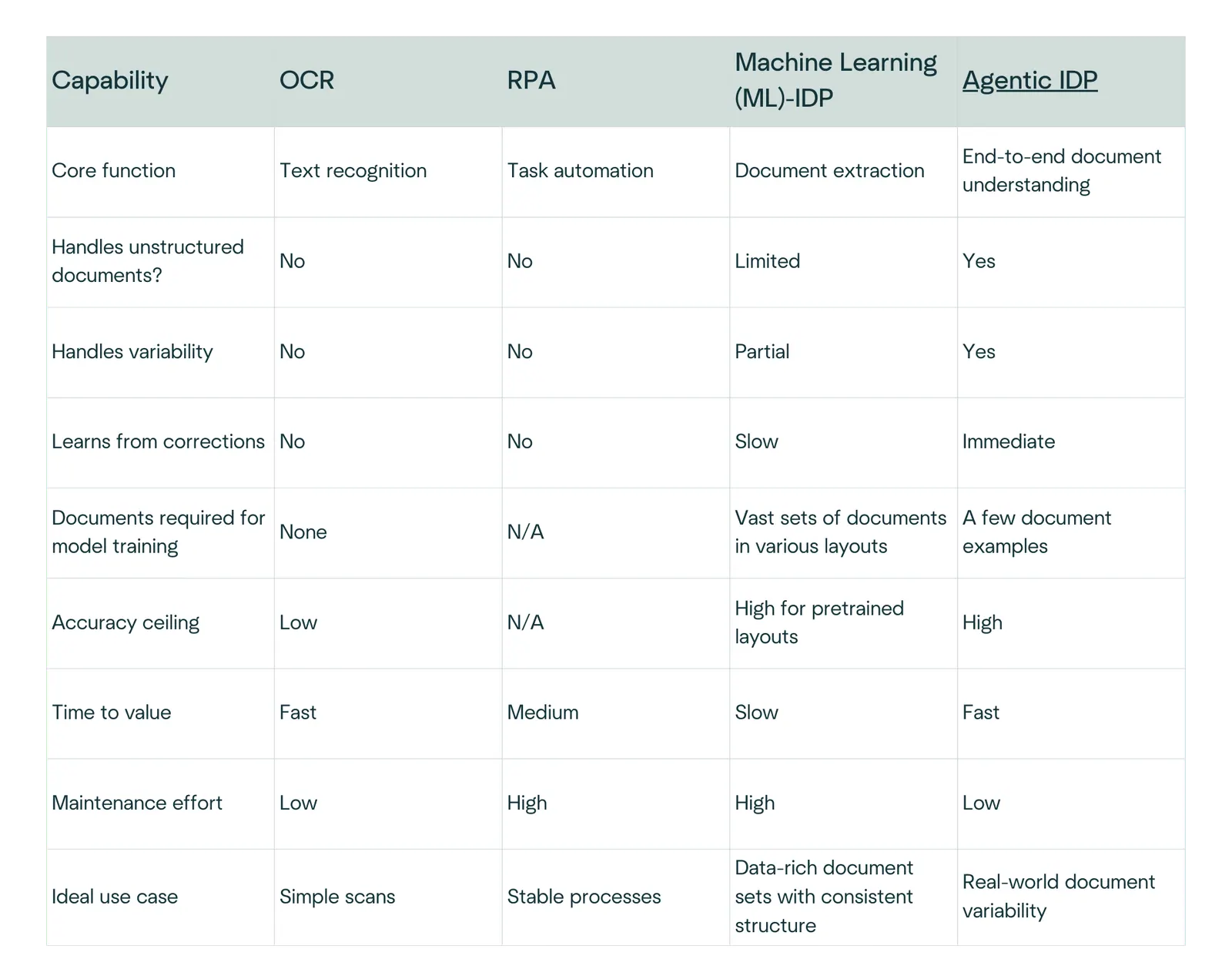
Where organizations go wrong when choosing OCR, RPA or IDP
Common mistakes organizations make when automating document processes include:
- Choosing OCR when what they really need is intelligent document understanding
- Over-automating with RPA on unstable inputs
- Attempting pure LLM extraction without grounding or validation
- Underestimating document variability
- Confusing text extraction with data extraction
These missteps waste budget, resources and erode internal confidence.
Choosing the right approach
Choosing between OCR, RPA and IDP solutions isn’t about chasing the newest technology. It’s about matching the approach to the reality of your documents, workflows and team capacity.
These questions help surface that reality quickly.
How variable are our documents? If layouts, formats or vendors change frequently, OCR and template-based approaches will break. High variability points toward IDP – and increasingly toward agentic IDP that adapts without retraining.
Where are exceptions slowing teams down? If most effort goes into handling edge cases, correcting outputs or validating data, the problem isn’t volume. It’s a lack of true document understanding, where OCR and RPA typically fall short.
What’s the cost of errors and rework? Errors don’t just create rework – they delay decisions, impact customers and reduce trust in automation. When accuracy matters downstream, brittle extraction quickly becomes a business risk.
How much maintenance can we absorb? If every document change requires template updates, retraining or pipeline tuning, the total cost of ownership rises fast. Low-maintenance systems matter.
How will we validate outputs? Extraction alone isn’t enough. Production workflows need grounding, validation and traceability. If you can’t explain why a value was extracted, it’s hard to trust it.
Can this scale without custom ML pipelines? Many solutions work in a demo but struggle in production. If scaling depends on ongoing model management, automation velocity slows and engineering becomes the bottleneck.
Agentic intelligent document processing is the right choice when the answers above point to complexity, risk and scale.
It’s typically the best fit when:
- Speed to value matters and long training cycles aren’t viable
- Documents vary heavily across layouts, sources and quality
- Teams are capacity-constrained, with limited appetite for ongoing maintenance
- Accuracy must exceed DIY or traditional ML approaches, because errors have real consequences
- Traceability and governance matter for compliance, trust and operational control
In these environments, higher accuracy means fewer corrections, more targeted human oversight and more straight-through processing – which is where automation delivers durable ROI.
Learn what IDP software features matter most
Download our guide to understand what IDP solutions are, compare how the software works across specific use cases and how to evaluate these technologies with confidence.
The future belongs to agentic AI IDP
Document automation has evolved from OCR and RPA to ML-based IDP and, now, beyond both.
Pure LLM approaches to document automation promised simplicity but fell short without grounding, validation and model memory. Agentic IDP systems combine with RAG to solve that gap, turning raw information into decision-ready data.
The economics have shifted. The tooling has matured. And the expectation is no longer ‘can we extract data?’ but ‘can we trust it at scale?’
That’s the era agentic IDP was built for.
If you’re ready to move faster than OCR, RPA or legacy IDP, explore how Affinda Platform approaches document automation today by trialling for free or talking to us.


