
Compare Amazon Textract and Affinda
Find out why G2 users score Affinda 4.9/5
When documents need a quick human touch - whether due to business logic checks or errors on your documents - your team can effortlessly review them via the intuitive human-in-the-loop validation interface.
Leverage Affinda's retrieval-augmented generation and benefit from the only AI document processing platform that instantly learns from every interaction, applying that knowledge to make human-like decisions and achieve impressive accuracy.
Create fully bespoke models with customized fields, extraction methods and transformations to match your exact business requirements in minutes, not weeks. Our AI agents help you configure everything quickly, letting you remain in complete control of the final tailored models.
Find out why G2 users score Affinda 4.9/5

Find out why Deep Analysis says Affinda “offers a rigorous alternative to hard-coded machine learning models or overly simplified LLM prompt-based tools”.
As the only IDP platform to apply agentic AI with persistent model memory, Affinda's platform ticks three key boxes: fast configuration, superior accuracy and the flexibility to extract data from any document in any format. That means you can create models to automate any document-heavy workflow in minutes, not months and integrate them with any business system.
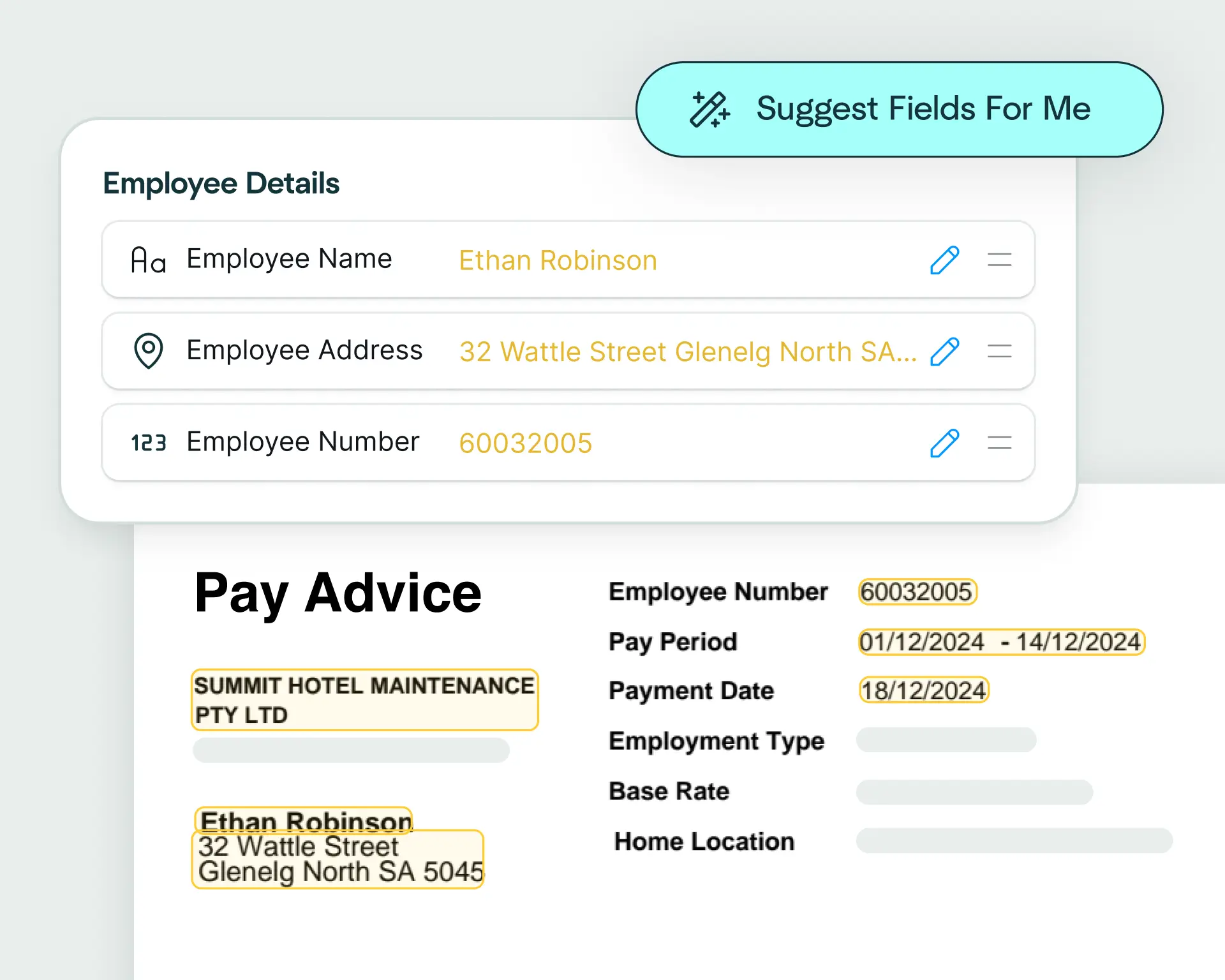
Upload a claims document and the Affinda Platform will predict the fields you need – like claimant details, policy number, incident date, totals and line items – so you can automate claims document processing in just a few clicks.
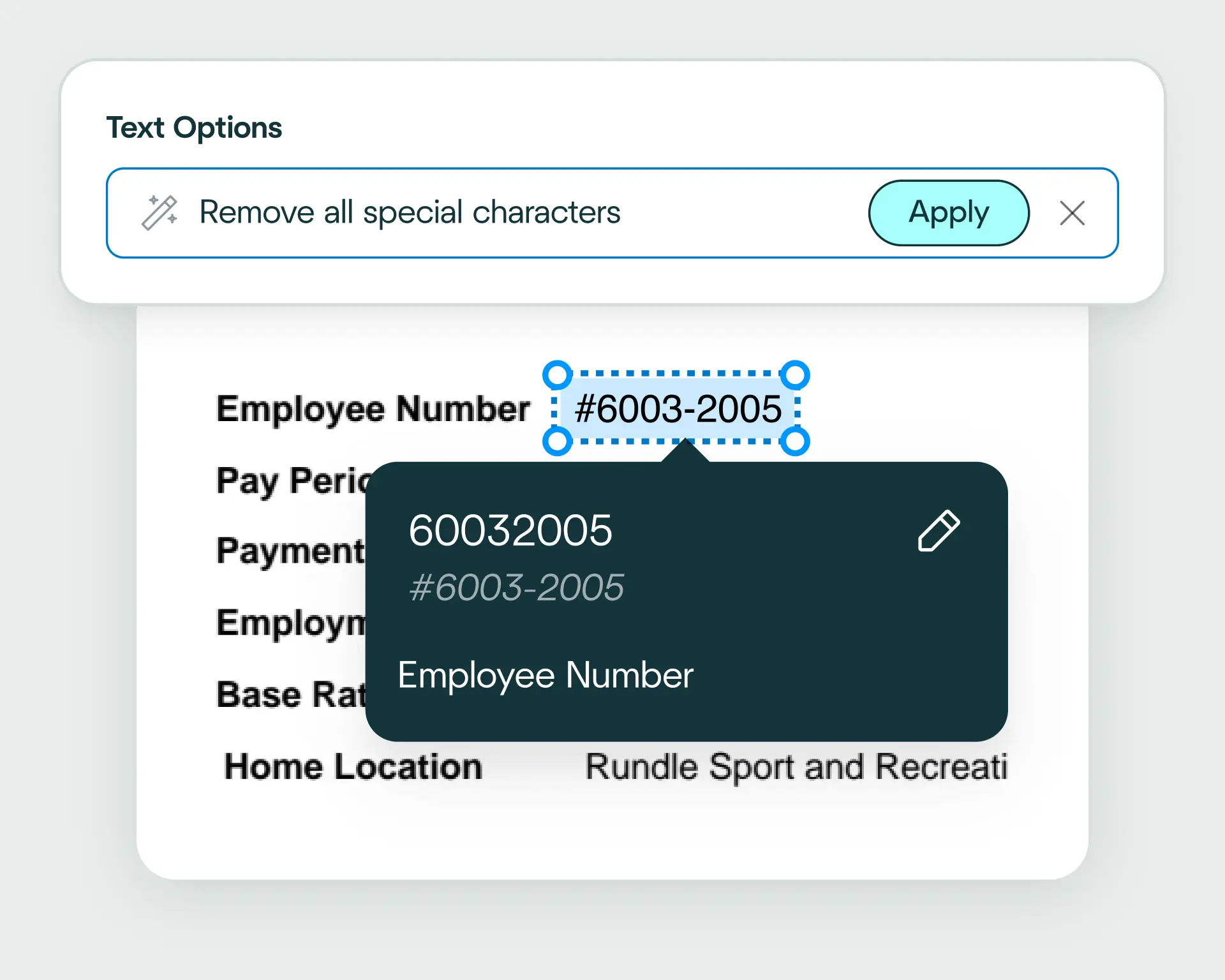
The platform checks extracted claims data against your business rules and transforms it into a format your claims management system expects. That way, it’s ready for workflows like coverage checks, reserving, routing and settlement.
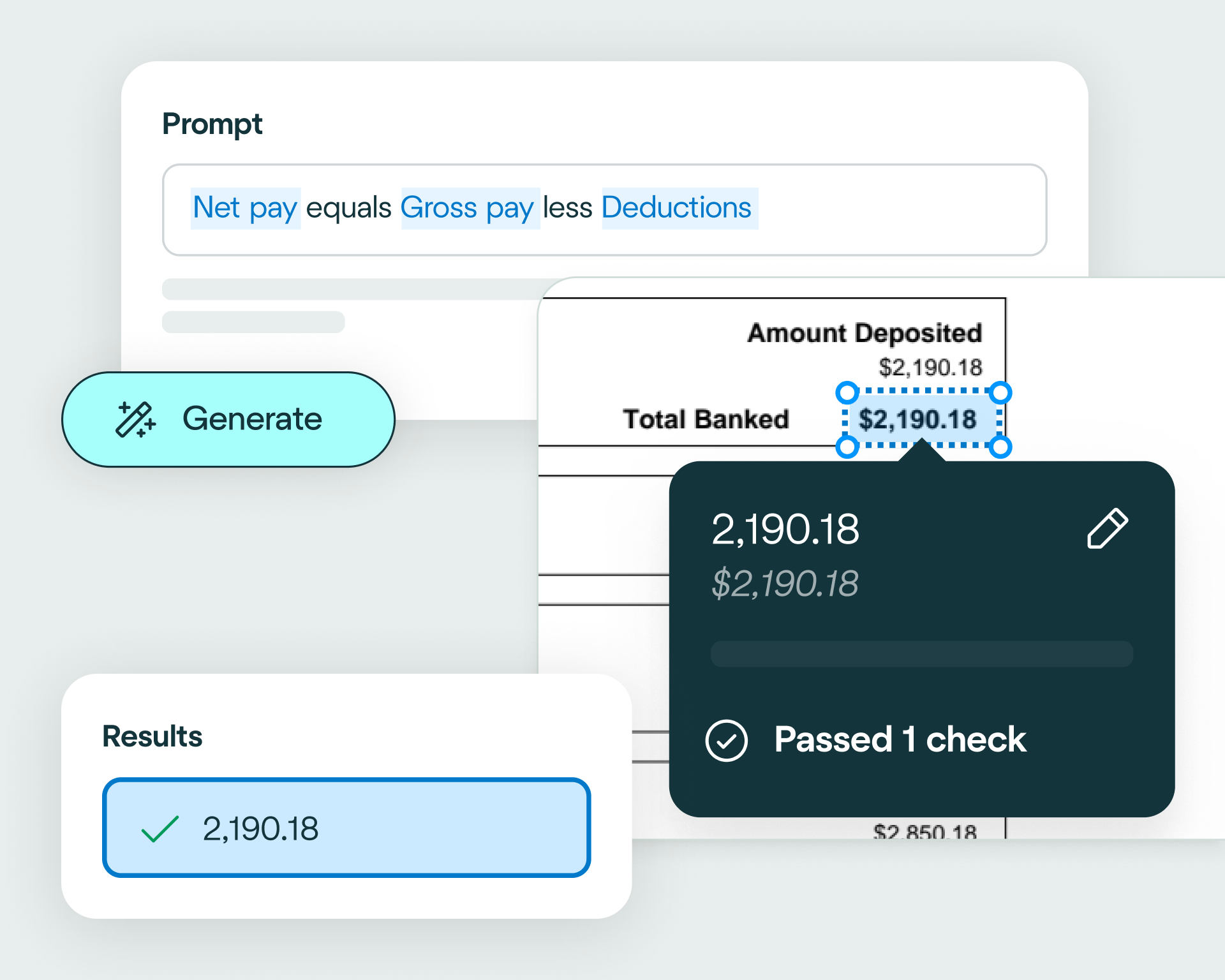
Use natural language to write validation rules that match your claims workflows, for example: flag missing fields; check policy numbers match correct formats; validate that document dates are within ranges; check financial consistency, such as line items summing correctly to totals.
Create integrations fast, even if you’re not a developer. Choose from 2800+ business systems and describe how you want your claims document processing integration to work, using natural language. Our AI Integrations Agent will generate the code to make it happen.
Easily connect Affinda Platform to your claims stack using our client libraries and APIs. Automatically generate type-safe Pydantic models or TypeScript interfaces tailored to your claims documents, so extracted fields map cleanly into your workflows.

Gain all the features from day one. With a free trial, discover how easy it is to extract any information from any document, fast.