Compare LLM alternatives - which IDP platform is right for you?

Why customers love Affinda
LLMs vs Affinda
| Feature | Description | Affinda | LLMs |
|---|---|---|---|
| Models and learning | |||
| LLM+ | Combines LLMs with RAG to deliver higher accuracy. | ✔ | ❌ |
| Instant learning | User corrections immediately improve future documents. | ✔ | ❌ |
| Document splitting and classification | Automatically separate files and classify incoming documents. | ✔ | ❌ |
| Complex tables and line items | Effectively handles complex simple and complex table structures. | ✔ | ❌ |
| Redaction | Remove sensitive content from PDFs. | ✔ | ❌ |
| Validation and governance | |||
| Natural language validation rules | Simply describe the rule and the platform applies it to the data. | ✔ | ❌ |
| Mapping to master data | Validate fields against the data in your system(s). | ✔ | ❌ |
| Human-in-the-loop validation interface | Users review exceptions using an intuitive UI. | ✔ | ❌ |
| Auditability and rule visibility | Every decision traceable for compliance. | ✔ | ❌ |
| Integration | |||
| No-code Agent | Chat to the Agent to create working integration code. | ✔ | ❌ |
| Comprehensive developer documentation | REST API model with quick starts, client libraries and developer tools. | ✔ | ✔ |
| Support and security | |||
| Affinda Academy | Guided tutorials, best practices and how-to’s. | ✔ | ❌ |
| AI Assistant | In-app assistant to help users through setup and configuration. | ✔ | ❌ |
| Compliant with global information security standards | ISO 27001:2022 certified and SOC 2 Type 2 and GDPR compliant. | ✔ | ✔ |
| Regional deployment options | Keep data in preferred regions or environments. | ✔ | ✔ |
| Pricing | |||
| Transparent, usage-based pricing | Clear consumption pricing, start small then scale. | ✔ | ✔ |
| Free trial | Test real documents before committing, no sales calls required. | ✔ | ✔ |
Last updated: 28/11/2025

Compare Affinda to other IDP solutions

Download the Deep Analysis vendor report about Affinda
Why Affinda is the best intelligent document processing platform
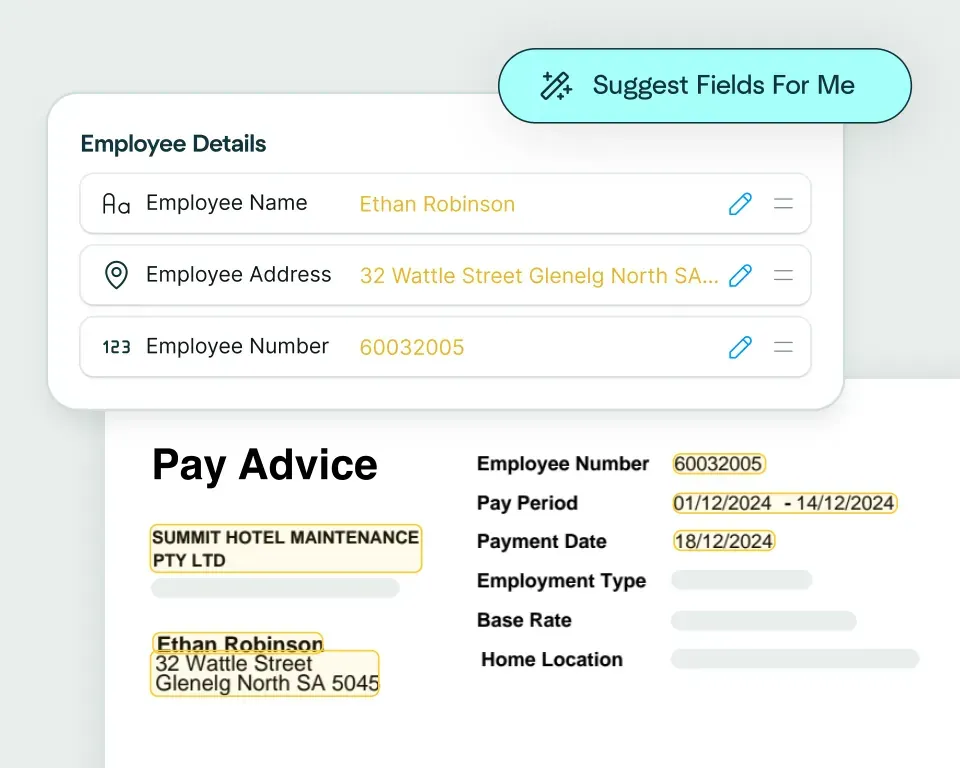
Create models in seconds
Validate and transform data
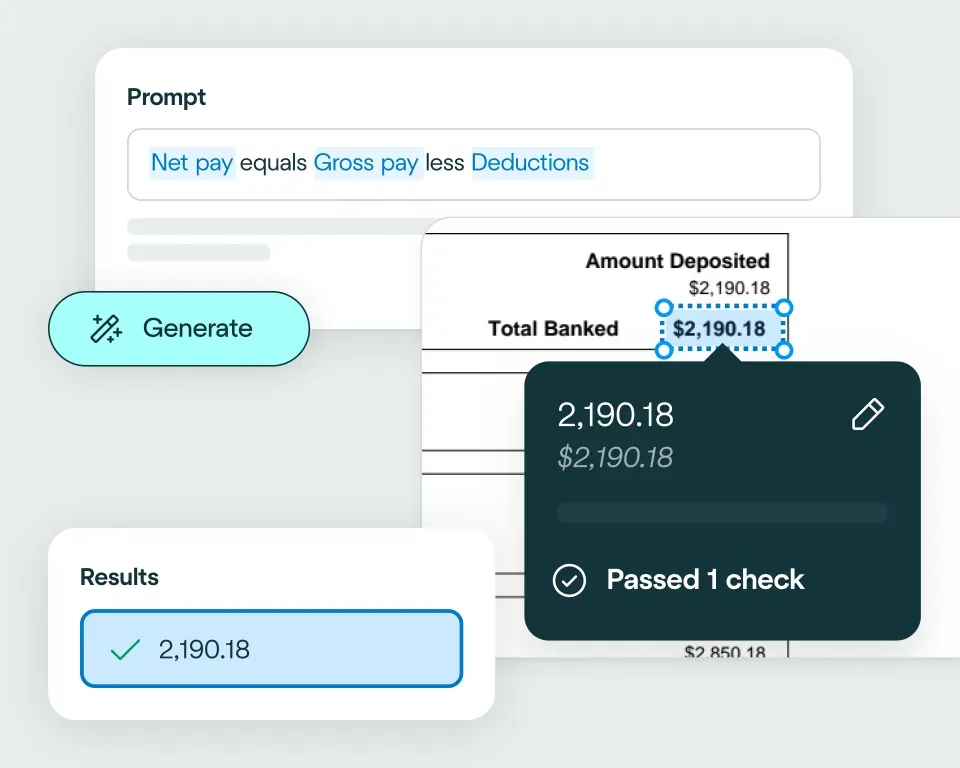
Apply your business logic
Pathway 1: Use our AI Integrations Agent
Pathway 2: Write your own code

No need to talk to sales. Get started now
Sign up for free
Upload documents
See the magic

Frequently asked questions
What are the top alternatives to using general-purpose LLMs for document extraction?
General-purpose large language models (LLMs) are increasingly used for document extraction, question answering and summarization. Teams experiment with LLMs to read PDFs, emails and business documents, often combined with optical character recognition (OCR) tools and custom code. Alongside this approach, organizations also consider intelligent document processing platforms, OCR engines and specialized document AI systems that are designed specifically to streamline document processing and reduce manual work.
Affinda stands out as a leading alternative because it is built from the ground up for document intelligence. The platform can extract any information from any document with industry-leading accuracy, learns instantly from every interaction and can be set up in minutes, not months. Instead of stitching together prompts, scripts and services around a general-purpose model, organizations can rely on Affinda's AI agents and model memory to provide a faster, more flexible and more accurate way to automate data extraction at scale.
What makes Affinda a stronger alternative to LLM-based document processing?
LLMs are powerful for natural language tasks and can be prompted to read, summarize and extract data from documents. Many teams start by building custom pipelines that combine LLMs, OCR, embedding stores and orchestration frameworks in order to turn document content into usable structured data. This can deliver promising prototypes but often introduces complexity as workflows grow.
Affinda is a strong alternative because it delivers fast setup, high accuracy and flexible automation without the engineering effort of creating an LLM stack from scratch. Affinda can process any document in any format with industry-leading precision, learns instantly from every interaction and builds reliable extraction models in minutes, not months. It performs classification, splitting, field detection and data transformation within a single platform, so teams get a production-ready solution that is easier to deploy, govern and scale than a custom LLM-based pipeline.
How does Affinda's accuracy and flexibility compare with LLM-based approaches to document extraction?
LLM-based approaches can work well for ad-hoc document analysis and interactive question answering, but they are not always optimized for field-level accuracy and consistent structured output. LLMs may hallucinate values, omit important fields, be sensitive to prompt changes or return different schemas from one document to the next. These characteristics make it harder to achieve the reliability required for straight-through processing in business workflows.
Affinda is designed for precise, predictable extraction. Our AI agents deliver industry-leading accuracy across structured, semi-structured and unstructured documents, including layouts with complex tables or multi-column content. Powered by advanced language models and Affinda's model memory, the platform learns instantly from every interaction and continues to refine predictions without lengthy retraining cycles. This combination provides the stability and flexibility that LLM-only solutions often lack, enabling a faster, more accurate way to automate document workflows.
How fast is Affinda to deploy compared to building document workflows on top of LLMs?
Building document workflows on top of general-purpose LLMs usually involves multiple components: OCR to convert images to text, chunking and context management for long documents, prompt design, error handling and integration into downstream systems. Aligning all these pieces into a robust production pipeline can take significant time and ongoing experimentation, especially when working with complex or varied documents.
Affinda is ready to use from day one. You can upload a single document and begin automating end-to-end processing almost immediately, without designing prompts or wiring together multiple services. Automatic splitting, classification, field detection and data transformation are built in, so teams move quickly from evaluation to production. This allows organizations to see ROI within weeks, not months, while avoiding the heavy lift associated with custom LLM-based workflows.
How does Affinda's setup and configuration compare to prompt- and model-based LLM workflows?
LLM workflows depend heavily on prompts, examples and orchestration logic. Teams must design and test prompts, tune model parameters, manage context limits and build validation rules to control hallucinations. When document types change or new fields are added, prompts and pipelines often need to be updated, which can turn into a continuous maintenance effort.
Affinda removes much of this complexity. There is no need for large pre-labeled datasets or intricate prompt hierarchies. Affinda lets you build accurate extraction models in minutes, not months: upload documents, confirm the fields you care about and the platform will identify and extract them consistently. Powered by advanced language models and model memory, Affinda learns instantly from every interaction and applies that knowledge without ongoing prompt tuning. The result is reliable extraction, rapid rollout and scalable document processing without the overhead of maintaining complex LLM logic.
Can Affinda handle the same document types people process with LLMs, and more?
Teams use LLMs to process a wide variety of documents by pasting text, uploading files or integrating separate PDF parsing tools. While this provides flexibility, LLMs alone are not optimized for OCR, complex layout understanding or structured table extraction, and they can struggle with long, multi-page or visually rich documents without significant additional engineering.
Affinda is built to handle all of these scenarios and more. The platform processes any document in any format, including:
- PDFs
- Scanned images
- Handwritten forms
- Structured templates
- Semi-structured and unstructured layouts
- Nested and multi-level tables
- Multi-page documents and document packs
Affinda's AI agents read text, understand context and extract information without relying on rigid templates or manual prompts, so even messy or non-standard documents can be processed with confidence. Because the platform learns instantly from every interaction, it adapts quickly to new document types without heavy configuration or retraining.
Common document types our customers use Affinda for include:
- Invoices
- Purchase orders
- Bank statements
- Payslips
- Proofs of delivery
- Bills of lading
- Packing slips
- Air waybills
- Certificates of origin
- Customs declarations
- Shipping labels
- Insurance and ACORD forms
- Credit reports
- Checks and remittance documents
- Certificates of analysis
How does Affinda handle new or unpredictable document layouts compared to LLM-based solutions?
LLM-based solutions can be prompted with examples to handle new layouts, but they do not inherently encode visual layout and reading order. Their performance depends heavily on how text was extracted upstream, how it is chunked and how well prompts describe the target structure. When layouts change or when documents contain complex tables, side-by-side columns or dense forms, maintaining accuracy can require frequent prompt adjustments and pipeline tuning.
The Affinda Platform is designed to process new or unfamiliar document layouts with minimal effort. Our AI agents have an advanced understanding of document layout and reading order, allowing them to interpret structure, context and positional cues with precision. This means the platform can extract information accurately even when documents vary significantly from one file to the next. Affinda's model memory learns instantly from every interaction, so it adapts to new formats without disrupting existing performance or requiring complex prompt redesign. This gives teams a faster, more scalable way to process unstructured, complex or completely unfamiliar layouts while maintaining consistently high accuracy.
Is switching from an LLM-based document extraction approach to Affinda difficult?
Many teams start with LLM-based experiments for document extraction by building internal scripts, prompt chains or prototypes that work on a small set of documents. Over time, these solutions can become harder to maintain as volumes grow, new document types appear and stakeholders require predictable accuracy, auditability and performance.
Switching to Affinda is straightforward. Affinda is designed to plug directly into your existing workflows with minimal disruption, so teams can move quickly without a heavy migration effort. You can upload your current documents and begin automating extraction in minutes, not months. There is no need to rebuild prompts, recreate complex orchestration logic or prepare large training datasets. Affinda identifies the information you want to extract, applies your business rules and transforms data into formats your downstream systems recognize, giving you a more robust foundation for long-term automation.
What use cases make Affinda a suitable alternative to LLMs for document workflows?
LLM-based approaches are useful for exploratory analysis, interactive question answering and one-off document reviews, but they can be difficult to operationalize for high-volume, repeatable workflows that demand consistent structure and accuracy. As organizations move from experimentation to production, they often look for a dedicated document AI platform that offers predictable results, governance and scale.
Affinda is a strong alternative across a wide range of document processing use cases, especially where speed, accuracy and flexibility are critical. The platform's ability to extract any information from any document, learn instantly from every interaction and handle complex or unstructured formats makes it suitable for both high-volume operations and specialized workflows.
Common use cases where organizations choose Affinda include:
Accounts payable and procurement
- Invoice processing
- Purchase order matching
- Reconciliation workflows
- Ideal where high accuracy and rapid rollout are essential
Financial services and lending
- Bank statements
- Credit reports
- Payslips
- Income or asset verification documents with highly variable structures
Logistics and supply chain
- Bills of lading
- Air waybills
- Packing slips
- Customs declarations
- Certificates of origin
- Shipping labels
- Commonly arrive scanned, handwritten or inconsistent; Affinda handles them reliably
Insurance
- ACORD forms
- Claims documents
- Supporting evidence requiring precise extraction from mixed layouts
Tax, payroll and compliance
- Tax forms and statutory documents
- Certificates and identity documents
- Ideal where data quality and low manual effort are key
Quality, operations and manufacturing
- Certificates of analysis
- Other technical documents with nested tables or non-standard layouts
In these scenarios, Affinda provides faster setup, higher accuracy and far less configuration effort than building and maintaining LLM-based pipelines, giving teams a more scalable and reliable path to automating document processing.
Is Affinda suitable for large enterprises and regulated industries that are experimenting with LLMs?
Many large enterprises and regulated organizations are experimenting with LLMs across different use cases, but they often need a dependable, compliant and auditable solution for core document processing. General-purpose LLMs can be useful for exploration yet may not provide the governance, consistency and control required for mission-critical workflows and regulated environments.
Yes. Affinda is well suited for large enterprises and regulated industries. The platform meets strict security and compliance standards while delivering high-accuracy automation across complex document workflows. Affinda provides enterprise trust without enterprise friction. You get ISO 27001:2022 certified security and SOC 2 and GDPR compliance without the complexity that often slows large vendors. The platform supports flexible deployment options and integrates cleanly with existing systems, so organizations can adopt AI document processing without disrupting established processes. With strong security, transparent pricing and flexible deployment, scaling Affinda becomes simple.
How does Affinda's pricing and total cost of ownership compare to building on top of LLM APIs?
Building document extraction on top of LLM APIs often introduces several cost drivers: token usage, add-on OCR services, orchestration layers, vector databases and the engineering time required to design and maintain prompts and pipelines. As document volumes grow or prompts evolve, it can become difficult to forecast spend and manage the overall cost of ownership.
Affinda's pricing is designed to be transparent, flexible and predictable. Instead of assembling multiple tools, you get a single consumption-based document intelligence platform where you only pay for what you use. There are no hidden fees, no complex packages and no long configuration cycles that inflate total cost of ownership. Organizations see value quickly because setup is fast, maintenance is minimal and models do not require large training datasets or prompt rebuilding. For teams looking for a cost-effective alternative to custom LLM builds, Affinda provides a simpler pricing structure, faster time to ROI and the flexibility to grow without heavy upfront investment.
Does Affinda offer enterprise-grade security?
Yes. Affinda offers enterprise-grade security. The platform is ISO 27001:2022 certified, SOC 2 compliant and adheres to global data privacy principles, including GDPR. These standards ensure that customer data is protected with the level of rigor expected by large enterprises and regulated industries.
Affinda is designed to keep your documents secure while removing the friction that often comes with enterprise tools. With strong security controls, flexible deployment options and a clear approach to data handling, organizations can adopt AI document processing with confidence.
Does Affinda offer a free trial for teams comparing Affinda with LLM-based approaches?
Yes. Affinda offers a free trial for teams evaluating alternatives to LLM-based document extraction. You can upload your own documents, test extraction quality and explore the platform for 14 days with no commitment. The trial includes full access to all features and lets you process up to 200 pages at no cost.
Because Affinda builds accurate models in minutes, you can see real results quickly and understand exactly how the platform performs on your workflows before moving to production. This makes it easy to validate accuracy, speed and ease of use as you compare Affinda with custom LLM-based solutions.