The document AI platform built for production
Explore the capabilities





Scope your workflow with Affinda
Describe, configure, automate
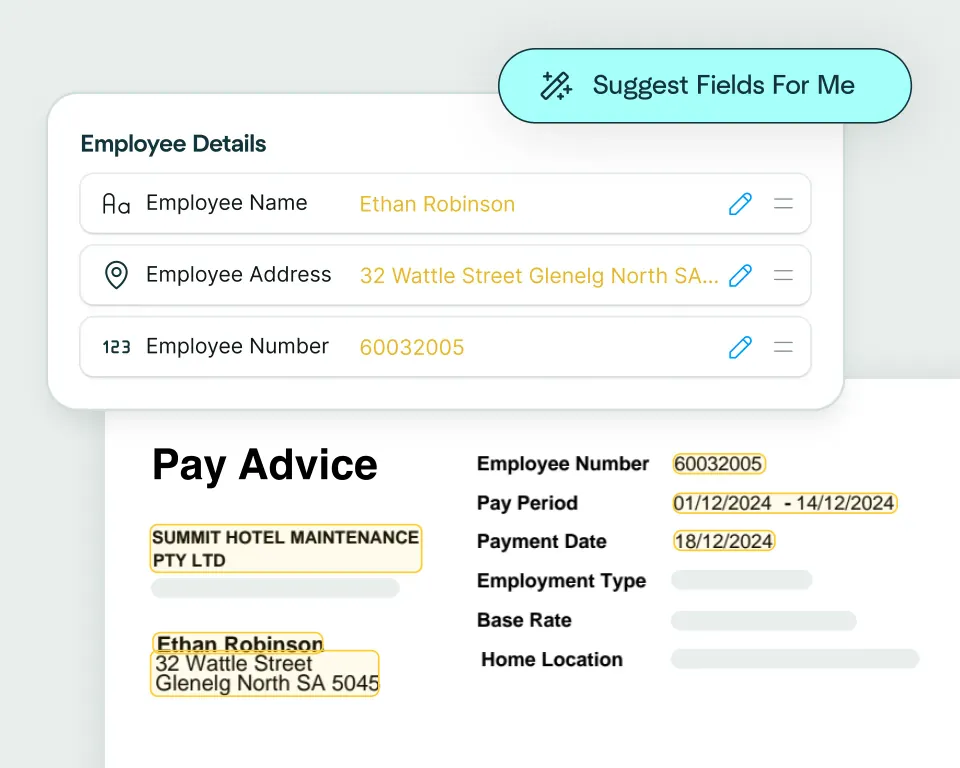
Configure with the Agent
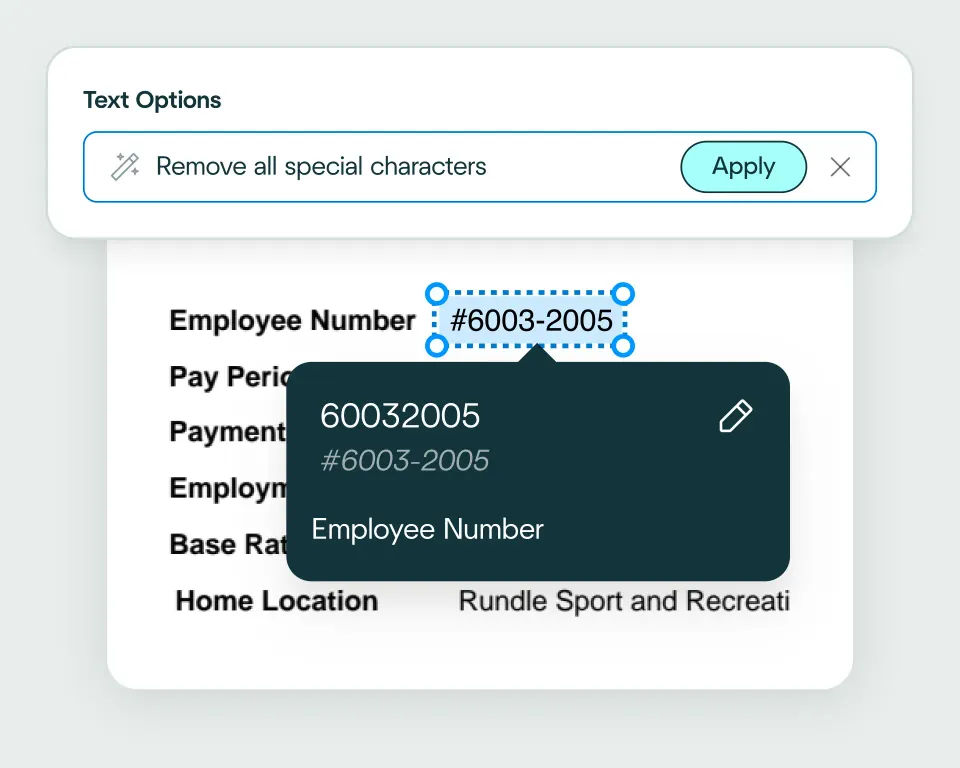
Cleanse and transform the data
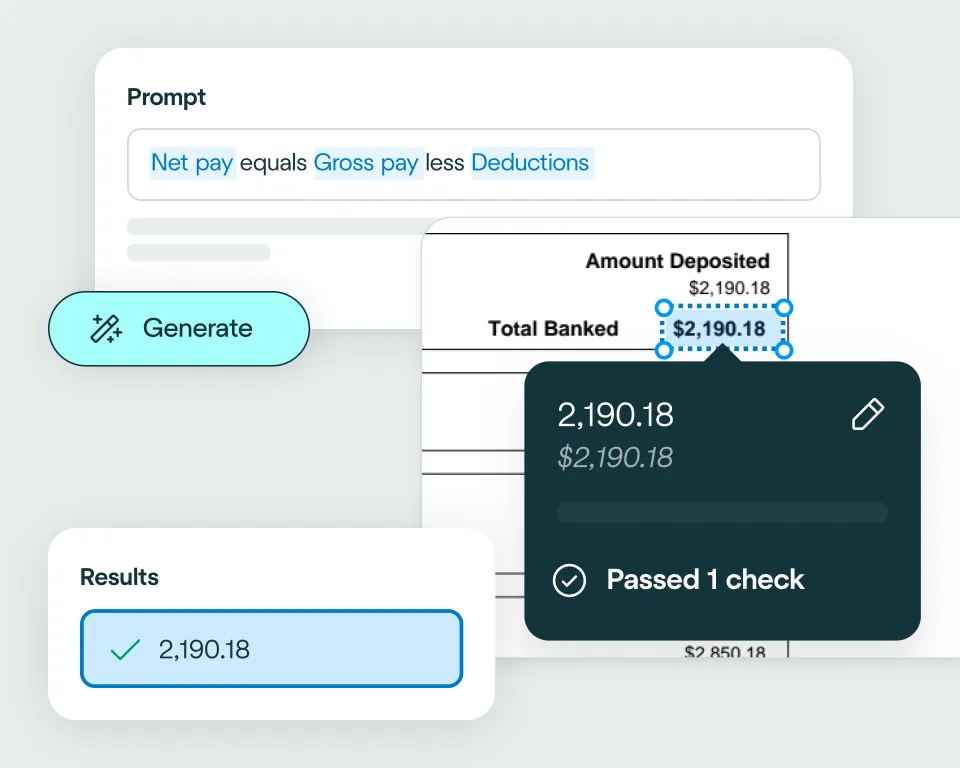
Apply your business logic
Integrate seamlessly with any business system
Pathway 1: Use the Affinda Agent
Pathway 2: Write your own code


Let AI agents do your document processing
More complete than LLMs alone
Frontier models power the extraction. Reliable output comes from everything around them: reading order, context selection, grounding to source, validation, and continuous learning. That's the production platform.

More advanced than legacy IDP
Traditional IDP requires months of template training and constant maintenance. The platform learns from every document and every correction, instantly. No templates, no retraining cycles.

Achieve straight-through processing
When validation rules pass, data flows straight through to your systems. When rules fail, exceptions are routed for review. Automation that scales with your confidence in the output.

Move fast and maintain control
Configure extraction models, validation rules, and integrations in natural language. No specialised ML resources required. Full audit trails and human oversight at every step.

Enterprise-grade security
ISO 27001:2022 certified, SOC 2 Type 2 and GDPR compliant. Global data centres for data residency, and flexible deployment options.

No need to talk to sales. Get started now
Sign up for free
Describe or upload
See decision-ready data

Scale with confidence
Combine the best of artificial and human intelligence


Clear, practical solutions
Industries
Use cases
Documents
- Account Statement
- ACORD Forms
- Air Waybill
- Articles of Incorporation
- ASIC Company Extract
- Balance Sheet
- Bank Check
- Bank Statement
- Beneficial Ownership Declaration
- Bill of Lading
- Bill of Materials
- Birth Certificate
- Cash Flow Statement
- Certificate of Analysis
- Certificate of Currency
- Certificate of Origin
- Claim Assessment Report
- Commercial Invoice
- Consignment Note
- Council Rates Notice
- Credit Application
- Credit Card Statement
- Credit Note
- Credit Report
- Customer Onboarding Form
- Customs Declaration
- Death Certificate
- Delivery Note
- Delivery Receipt
- Divorce Decree
- Financial Report
- Financial Statements
- Form 1040
- Form 1099
- Form 4506-C
- Form 941
- Form W-2
- Form W-9
- Health Insurance Claim
- I-9 Form
- ID Card
- Insurance Certificate
- Insurance Policy Schedule
- Invoice
- KYC Form
- Laboratory Test Report
- Lease Agreement
- Loan Application Form
- Loan Contract
- Marriage Certificate
- Medical Prescription
- Medical Record
- Mortgage Application Form
- Mortgage Deed
- Operating Agreement
- Order Confirmation
- Packing Declaration
- Packing Slip
- Passport
- PAYG Payment Summary
- Payslip
- Profit and Loss Statement
- Proof of Address
- Proof of Delivery
- Proof of Funds Letter
- Proof of Identity
- Proof of Income
- Property Title Deed
- Purchase Order
- Quotation
- Receipt
- Regulatory Filings
- Remittance Advice
- Rental Statement
- Residence Permit
- Safety Data Sheet
- Sales Order
- Shipping Label
- Statement of Work
- Supplier Onboarding Form
- Tax Notice of Assessment
- Tax Return
- Timesheet
- Training Certificate
- Travel Visa
- Trust Deed
- UK P11D
- UK P45
- UK P60
- UK SA100
- UK SA302
- Utility Bill
- VAT Return
- Verification of Employment Form
- W-8BEN
- W-8BEN-E
- Warranty Claim
- Work Order