
Combine the best of artificial and human intelligence
99%+
accuracy in data and information extraction
10+
years of IP combined with the latest AI innovations
500M+
documents processed
50+
languages supported, empowering customers globally
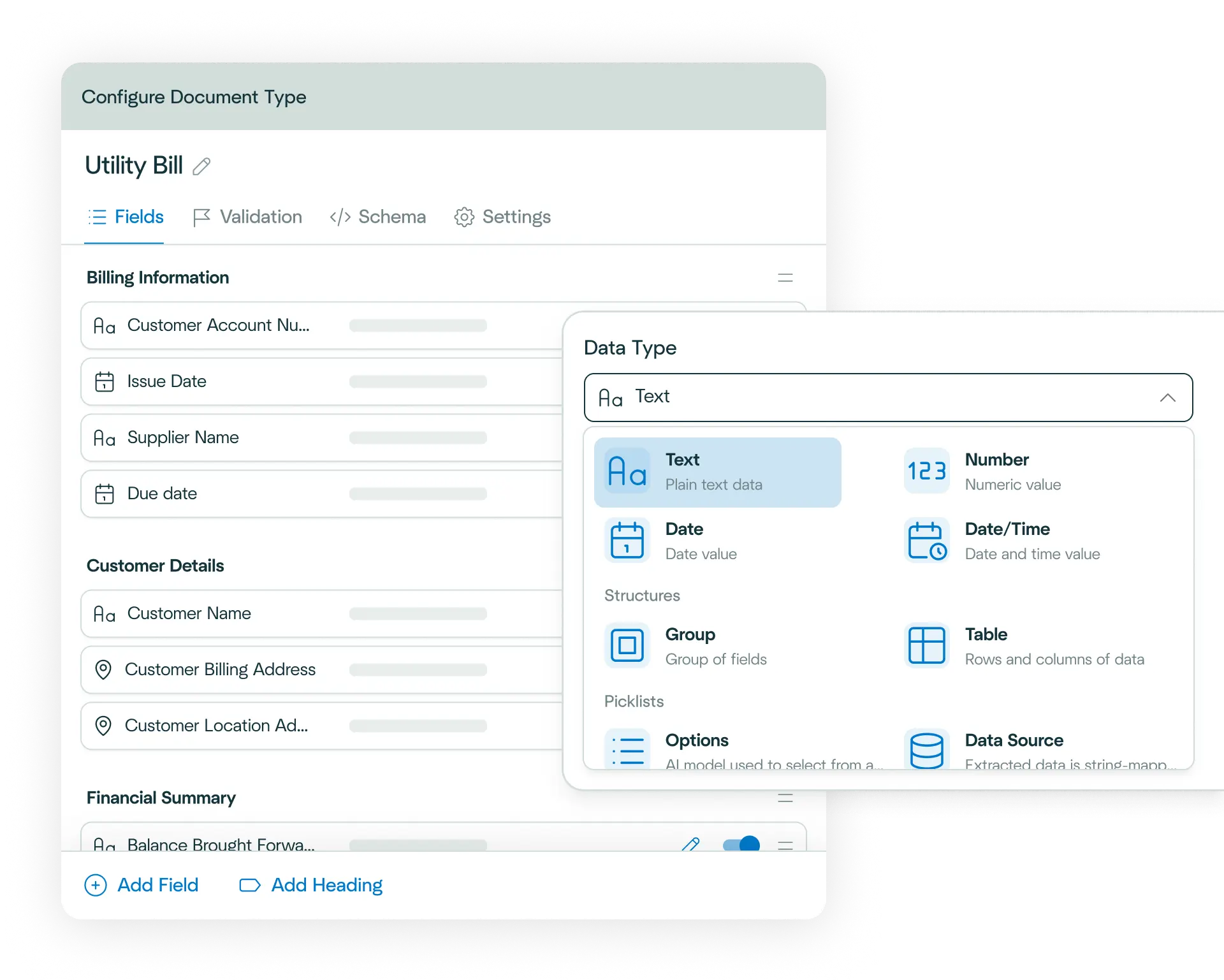
Upload a passport and watch as Affinda instantly predicts the data fields you want to extract, helping you automate passport data extraction in just a few clicks.
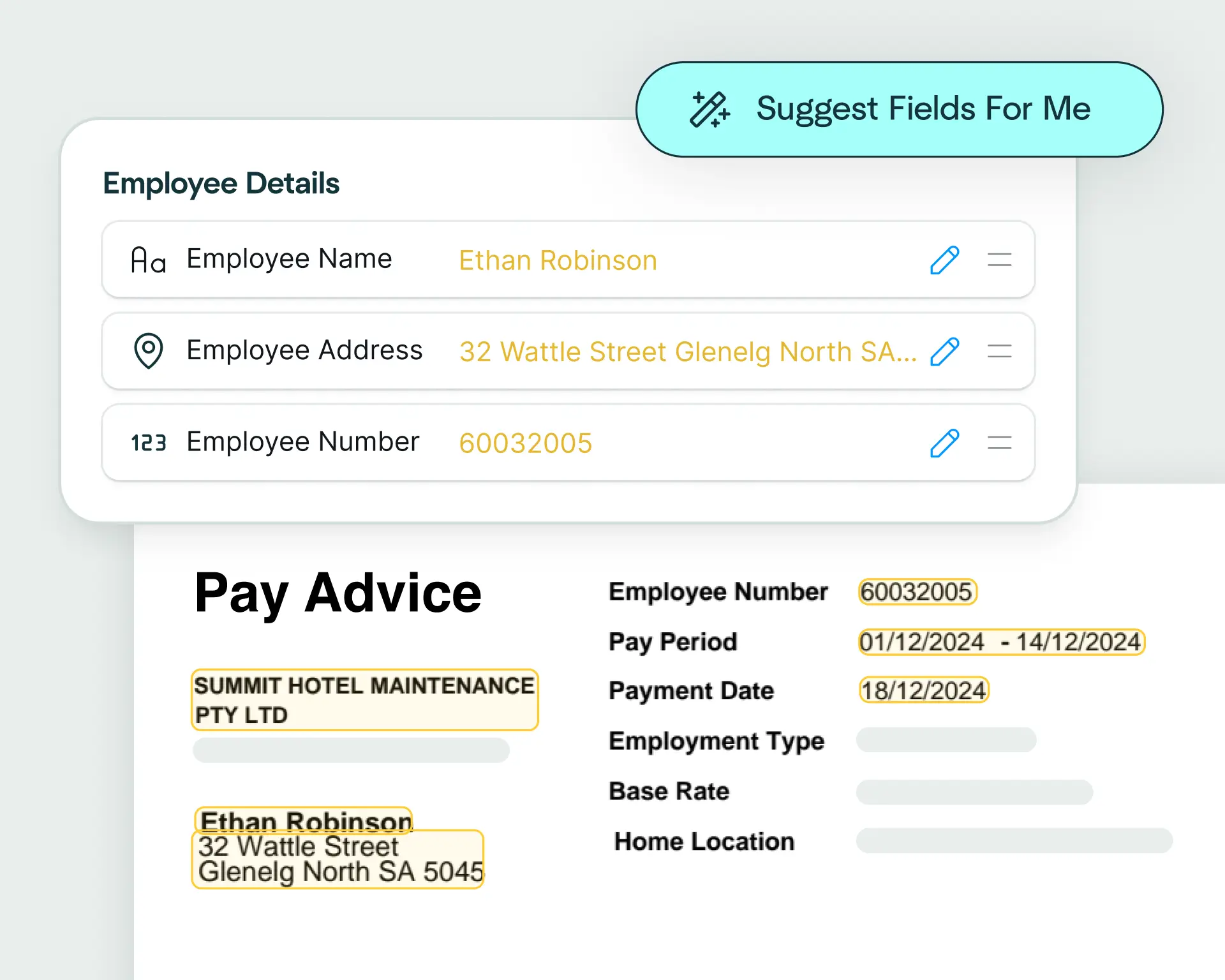
Affinda automatically converts extracted passport data into the format your downstream systems expect – whether that's your KYC platform, HRIS or compliance tools. Need something specific? Use natural language to describe your ideal output structure.
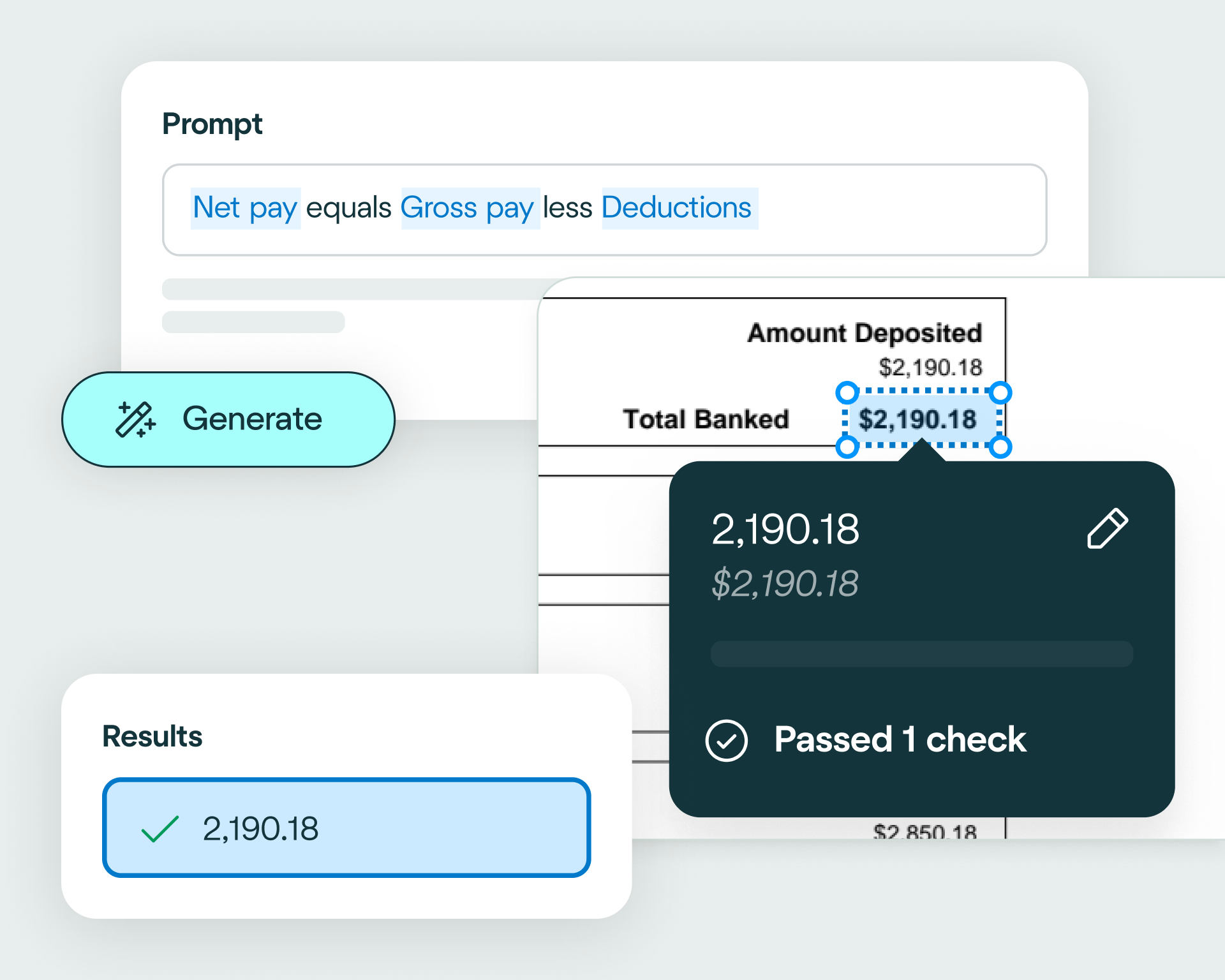
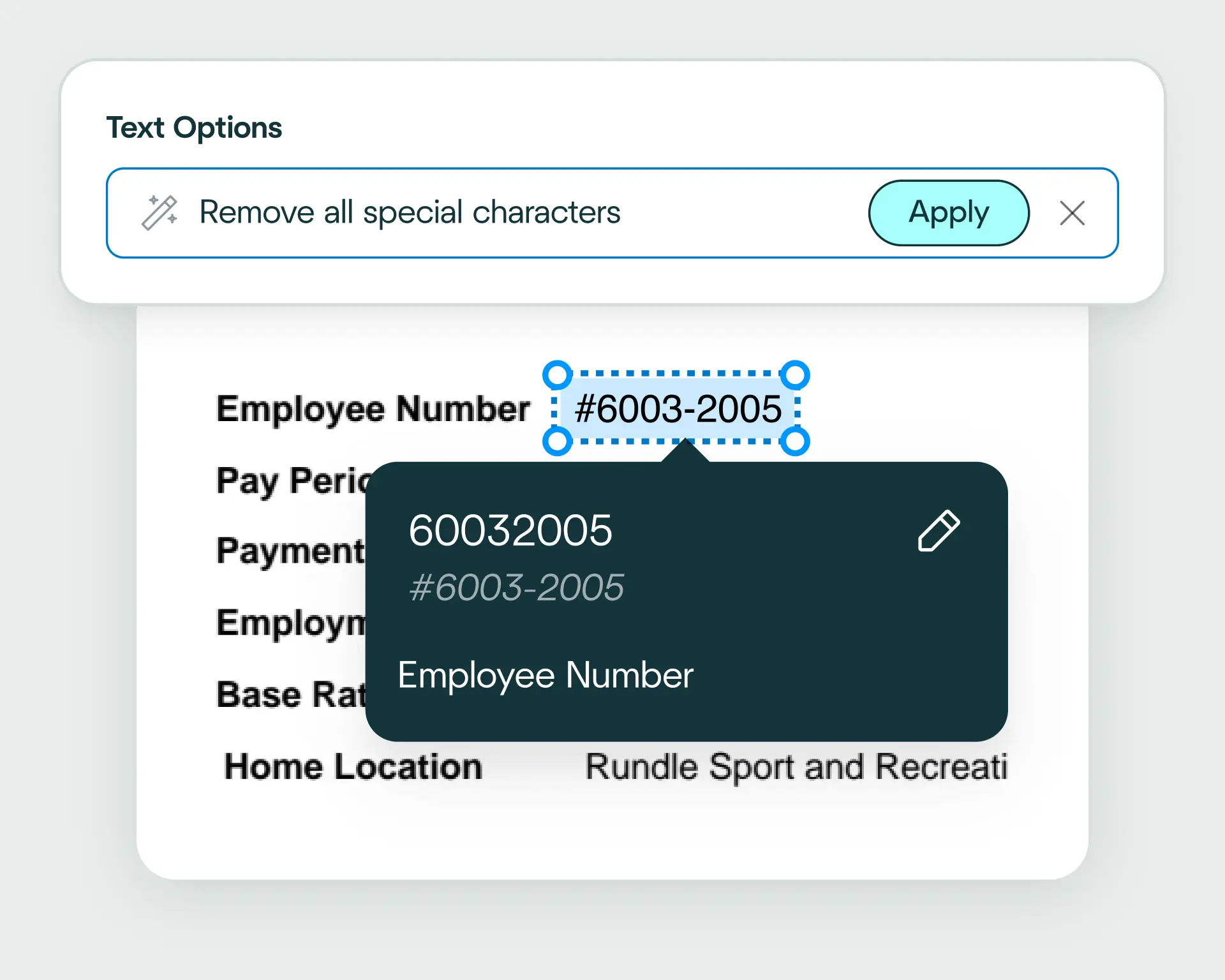
Use natural language to write validation rules and apply your business logic to passport data. This ensures the output meets your compliance requirements and enables fast, accurate identity verification.
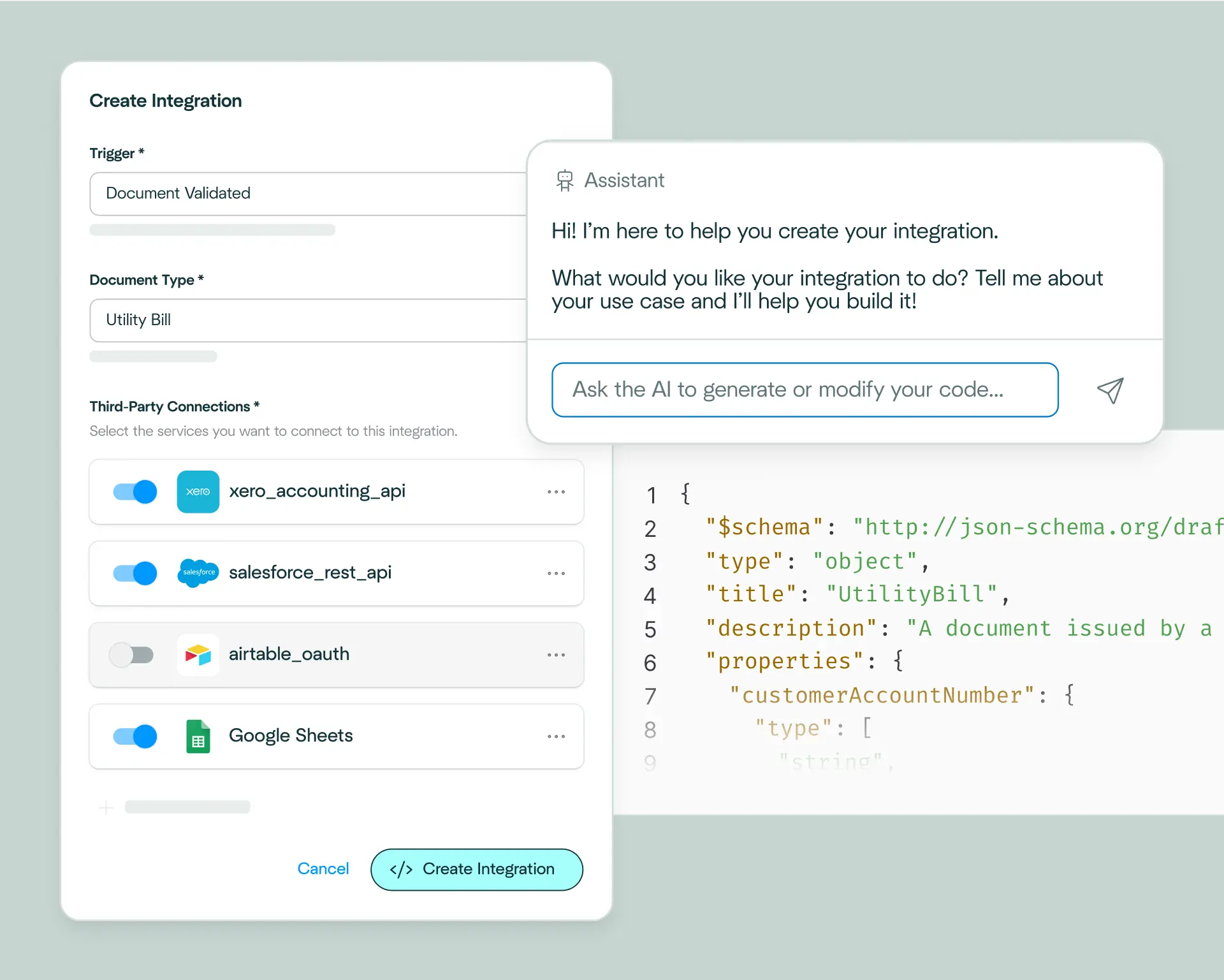
Build passport processing integrations without writing code yourself. Pick from 400+ business systems and explain what you need in plain language. Affinda's AI Integrations Agent translates your requirements into working code automatically.
Easily connect Affinda with your systems using our client libraries. Automatically generate type-safe Pydantic models or TypeScript interfaces tailored to your passport processing needs.

accuracy in data and information extraction
years of IP combined with the latest AI innovations
documents processed
languages supported, empowering customers globally
With a free trial, discover how easy it is to extract any information from any document, fast.

Affinda has removed the laborious workload from our accounts staff, who now focus on quality assurance and management of any outliers.
- Nathaniel Barrs, CTO, PSC Insurance
reduction in manual work
more invoices processed with no added staff
Enhanced auditability and tracking of invoice approvals



Customer satisfaction is always our top priority, and Affinda has helped us achieve that by eliminating phone calls, manual handling, and delays.
- Jorg Both, Head of Business Systems, Northline
proof of delivery documents processed annually
of documents straight-through processed in the first weeks
Automatic validation of documents against ERP system

.webp)

Affinda's ongoing improvements in its AI models demonstrate its innovative approach in Document AI.
– Michael Zhao, AI Product Manager, SEEK



Affinda’s support and expertise were invaluable… The experience working with Affinda was excellent.
- Nick Tran, Business Analyst, StateCover Mutual
documents processed annually
different document types
Enhanced auditability and tracking of invoice approvals

.webp)

The results have spoken for themselves. I recommend Affinda to anyone looking to enhance their product or business with AI capability.
- Steve O’Keeffe, CTO, Felix
reduction in manual data input
reduction in compliance data errors
compliance documents processed annually
